
I am an ELLIS PhD student in the Computer Vision Lab at the University of Amsterdam, advised by Prof. Dimitris Tzionas. My research focus on 3D Human Object Interaction (HOI) synthesis, while I am also interested in reconstructing 4D HOIs from videos. Before joining UvA I had the great opportunity to spend 4 months as a research intern at Simon Fraser University working together with Prof. Manolis Savva. Prior to that I completed my Master at the University of Patras collaborating with Prof. Emmanouil Psarakis, while also working as a Lead Quality Assurance Enginner at Hellenic Air Force. I am also a passionate windsurfer. However, when the sea and wind are not there I enjoy spending my time running or going to the gym.
Publications

Recovering 3D object pose and shape from a single image is a challenging and
ill-posed problem. This is due to strong (self-)occlusions, depth ambiguities,
the vast intra- and inter-class shape variance, and the lack of 3D ground truth
for natural images. Existing deep-network methods are trained on synthetic datasets
to predict 3D shapes, so they often struggle generalizing to real-world images.
Moreover, they lack an explicit feedback loop for refining noisy estimates, and
primarily focus on geometry without directly considering pixel alignment. To tackle
these limitations, we develop a novel render-and-compare optimization framework,
called SDFit. This has three key innovations: First, it uses a learned category-specific
and morphable signed-distance-function (mSDF) model, and fits this to an image by
iteratively refining both 3D pose and shape. The mSDF robustifies inference by
constraining the search on the manifold of valid shapes, while allowing for arbitrary
shape topologies. Second, SDFit retrieves an initial 3D shape that likely matches
the image, by exploiting foundational models for efficient look-up into 3D shape
databases. Third, SDFit initializes pose by establishing rich 2D-3D correspondences
between the image and the mSDF through foundational features. We evaluate SDFit on
three image datasets, i.e., Pix3D, Pascal3D+, and COMIC. SDFit performs on par with
SotA feed-forward networks for unoccluded images and common poses, but is uniquely
robust to occlusions and uncommon poses. Moreover, it requires no retraining for
unseen images. Thus, SDFit contributes new insights for generalizing in the wild.
@inproceedings{antic2025sdfit,
title = {{SDFit}: {3D} Object Pose and Shape by Fitting a Morphable {SDF} to a Single Image},
author = {Anti\'{c}, Dimitrije and Paschalidis, Georgios and Tripathi, Shashank and Gevers, Theo and Dwivedi, Sai Kumar and Tzionas, Dimitrios},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2025},
}
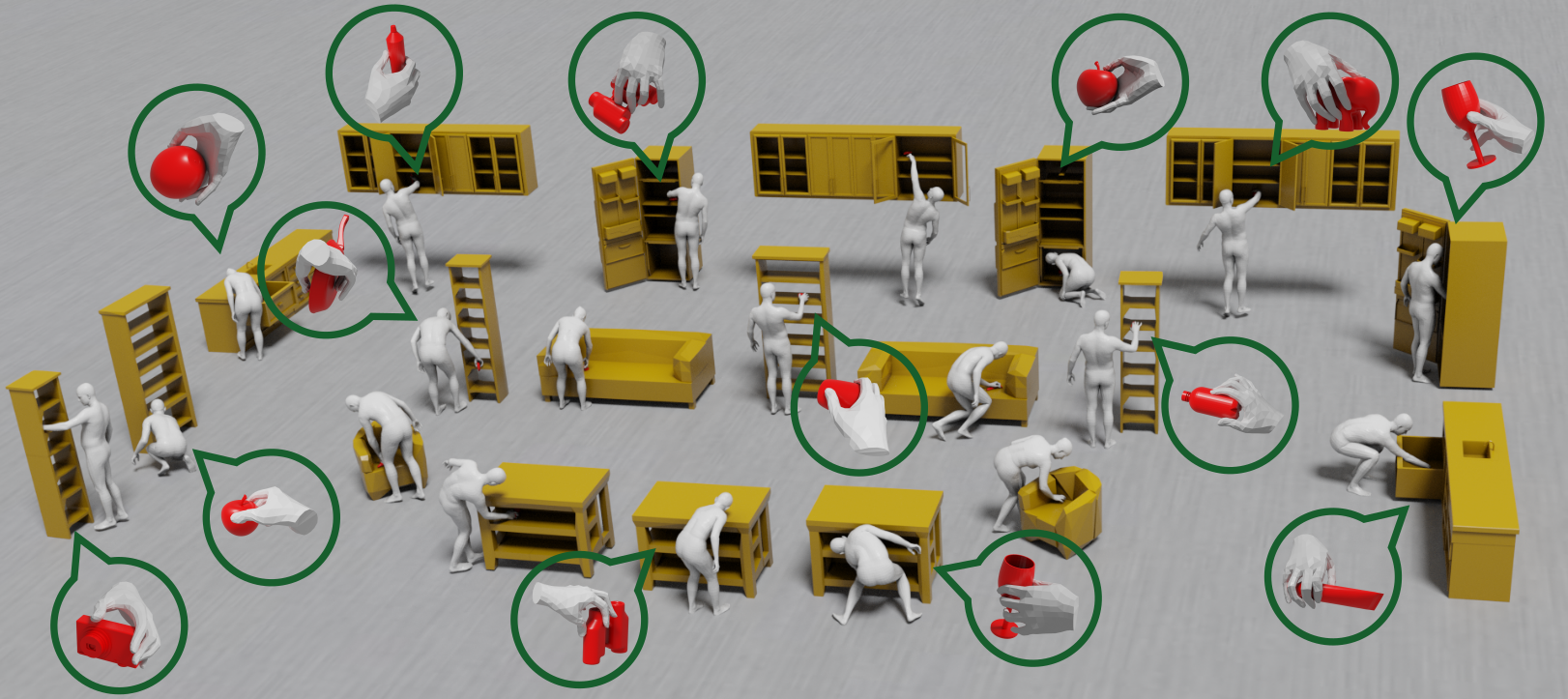
Synthesizing 3D whole bodies that realistically grasp objects is useful for
animation, mixed reality, and robotics. This is challenging, because the hands
and body need to look natural w.r.t. each other, the grasped object, as well as
the local scene (i.e., a receptacle supporting the object). Moreover, training
data for this task is really scarce, while capturing new data is expensive.
Recent work goes beyond finite datasets via a divide-and-conquer approach; it
first generates a “guiding” right-hand grasp, and then searches for bodies that
match this. However, the guiding-hand synthesis lacks controllability and
receptacle awareness, so it likely has an implausible direction (i.e., a body
can’t match this without penetrating the receptacle) and needs corrections
through major post-processing. Moreover, the body search needs exhaustive
sampling and is expensive. These are strong limitations. We tackle these with a
novel method called CWGrasp. Our key idea is that performing geometry-based
reasoning “early on,” instead of “too late,” provides rich “control” signals
for inference. To this end, CWGrasp first samples a plausible
reaching-direction vector (used later for both the arm and hand) from a
probabilistic model built via ray-casting from the object and collision
checking. Then, it generates a reaching body with a desired arm direction, as
well as a “guiding” grasping hand with a desired palm direction that complies
with the arm’s one. Eventually, CWGrasp refines the body to match the “guiding”
hand, while plausibly contacting the scene. Notably, generating
already-compatible “parts” greatly simplifies the “whole”. Moreover, CWGrasp
uniquely tackles both right and left-hand grasps. We evaluate on the GRAB and
ReplicaGrasp datasets. CWGrasp outperforms baselines, at lower runtime and
budget, while all components help performance. Code and models are available for
for research.
@inproceedings{paschalidis2025cwgrasp,
title={{3D} {W}hole-Body Grasp Synthesis with Directional Controllability},
author={Paschalidis, Georgios and Wilschut, Romana and Anti\'{c}, Dimitrije and Taheri, Omid and Tzionas, Dimitrios},
booktitle = {{International Conference on 3D Vision (3DV)}},
year={2025}
}