LEXIS: LatEnt ProXimal Interaction Signatures for 3D HOI from an Image
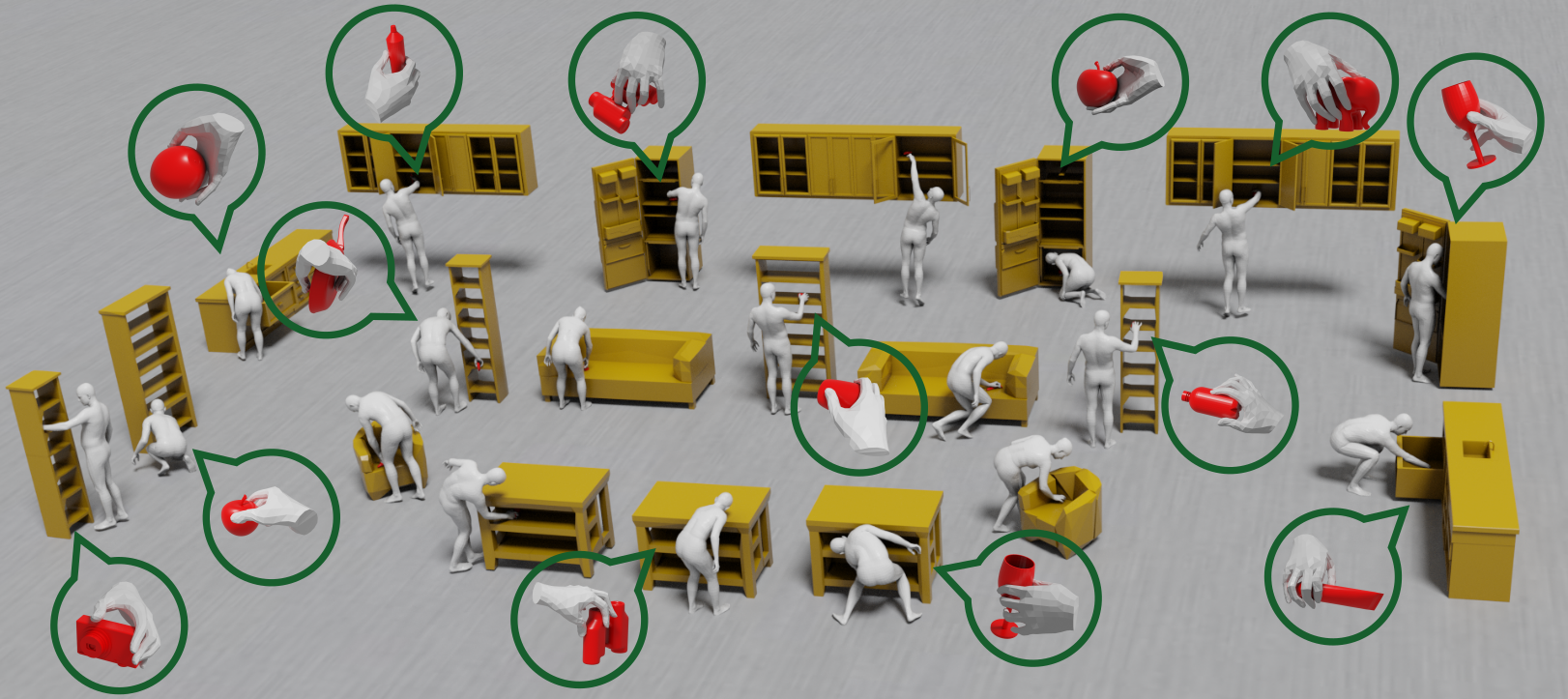
Reconstructing 3D Human-Object Interaction from an RGB image is essential for perceptive systems. Yet, this remains challenging as it requires capturing the subtle physical coupling between the body and objects. While current methods rely on sparse, binary contact cues, these fail to model the continuous proximity and dense spatial relationships that characterize natural interactions. We address this limitation via InterFields, a representation that encodes dense, continuous proximity across the entire body and object surfaces. However, inferring these fields from single images is inherently ill-posed. To tackle this, our intuition is that interaction patterns are characteristically structured by the action and object geometry. We capture this structure in LEXIS, a novel discrete manifold of interaction signatures learned via a VQ-VAE. We then develop LEXIS-Flow, a diffusion framework that leverages LEXIS signatures to estimate human and object meshes alongside their InterFields. Notably, these InterFields help in a guided refinement that ensures physically-plausible, proximity-aware reconstructions without requiring post-hoc optimization. Evaluation on Open3DHOI and BEHAVE shows that LEXIS-Flow significantly outperforms existing SotA baselines in reconstruction, contact, and proximity quality. Our approach not only improves generalization but also yields reconstructions perceived as more realistic, moving us closer to holistic 3D scene understanding.
@article{antic2026lexis,
title = {{LEXIS}: {LatEnt} {ProXimal} Interaction Signatures for {3D} {HOI} from an Image},
author = {Anti\'{c}, Dimitrije and Budria, Alvaro and Paschalidis, Georgios and Dwivedi, Sai Kumar and Tzionas, Dimitrios},
journal = {arXiv preprint arXiv:2604.20800},
year = {2026},
}